一、起因 舍友谈了女朋友,女朋友好像是学医的。然后她们有一个非常扯淡的工作,作为班干部要把word给弄成excal
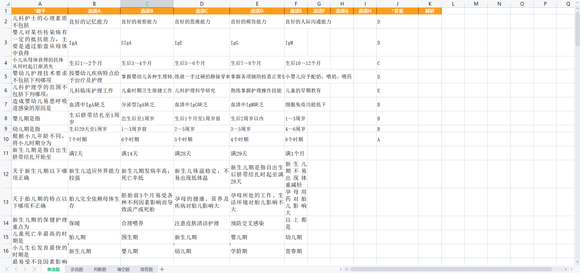
像这样(舍友手搓的):
而这玩意有足足900+道题,如果说手动写入那简直是苦难深重(而我的舍友因为爱情的力量还是坚持搞了大概五分之一,爱情太强大了,强大到能够冲昏头脑~~)
于是在一天下午舍友向我询问能不能自动转换,我想了想寒假学的数据处理和写数据库用的一些方法 拿正则套一下就行了 我说应该没问题来吧,然后就把这件事接了下来,之后他给我发了word文件我看了看,格式非常整洁很容易把正则套上去。那么 理论存在实践开始!
二、学习准备 之前没有操作过docx文件,所以去查了一下如何去操作docx文件。需要下载一个叫python-docx的库那么
然后导入库
1 from docx import Document
这里我用pycharm 结果装了给docx的库 和python-docx 不是一个库请注意!
1 doc = Document("D:\垃圾项目\儿科.docx")
Document(docx文件路径)
会创建一个Document的对象打开文件
这时候我们
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 doc = Document("D:\垃圾项目\儿科.docx") for i, paragraph in enumerate(doc.paragraphs[:55]): print(i, paragraph.text) 0 第一章:绪论 1 一、单项选择题 2 1. 儿科护士的心理素质不包括 3 A.良好的记忆能力 4 B.良好的观察能 5 C.良好的思维能力 6 D.良好的模仿能力 7 E.良好的人际沟通能力 8 2. 婴儿对某些传染病有一定的抵抗能力,主要是通过胎盘从母体中获得 9 A.IgA 10 B.SIgA 11 C.IgE 12 D.IgG 13 E.IgM 14 3. 小儿从母体获得的抗体从何时起日渐消失 15 A.生后1~2个月 16 B.生后3~4个月 17 C.生后5~6个月 18 D.生后7~8个月 19 E.生后10~12个月 20 4 .婴幼儿护理技术要求不包括下列哪项 21 A.按婴幼儿疾病特点给予治疗及护理 22 B.掌握婴幼儿各种生理特点和疾病特点 23 C.练就一手过硬的静脉穿刺技术 24 D.掌握各项辅助检查正常值 25 E.小婴儿应予配奶、喂奶、喂药 26 5.儿科护理学的范围不包括下列哪项: A.儿科临床护理工作 27 B.儿童时期卫生保健工作 28 C.儿科护理科学研究 29 D.熟练掌握护理操作技能 30 E.儿童的早期教育 31 6.造成婴幼儿易患呼吸道感染的原因是 32 A.血清中IgA缺乏 33 B.分泌型IgA缺乏 34 C.血清中IgG缺乏 35 D.血清中IgM缺乏 36 E.细胞免疫功能低下 37 7. 婴儿期是指 38 A.生后脐带结扎至1周岁 39 B.出生后至1周岁 40 C.生后1个月至1周岁前 41 D.生后2周岁以内 42 E.1~3周岁 43 8.幼儿期是指 44 A.生后29天至1周岁 45 B.1~3周岁前 46 C.2~5周岁 47 D.3~5周岁 48 E.4~6周岁 49 9.根据小儿年龄不同,将小儿时期分为 50 A.7个时期 51 B.6个时期 52 C.5个时期 53 D.4个时期 54 E.8个时期
非常顺利的拿到了前五十行的信息
实际操作: 能够拿到数据那么接下来就非常简单了去匹配格式,然后去进行处理
这时候就要用到正则表达式了
观察文档发现:
题型以大写数字开头
题目以普通数字+.开头
选项以字母.开头
整理好思路开始写正则:
1 2 3 4 5 6 black_char = re.compile("[\s\u3000\xa0]+") chinese_nums_rule = re.compile("[一二三四]、(.+)") title_rule = re.compile("\d+.") option_rule = re.compile("[ABCDEF]") option_rule_search = re.compile("^.+?$")
好让我们把正则匹配输出一下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 for paragraph in doc.paragraphs[0:55]: # 去除空白字符,将全角字符转半角字符,并给括号之间调整为中间二个空格 line = black_char.sub("", paragraph.text).replace( "(", "(").replace(")", ")").replace(".", ".").replace("()", "( )") # 对于空白行就直接跳过 if not line: continue if title_rule.match(line): print("题目", line) elif option_rule.match(line): print("选项", option_rule_search.findall(line)) else: chinese_nums_match = chinese_nums_rule.match(line) if chinese_nums_match: print("题型", chinese_nums_match.group(1))
输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 题型 单项选择题 题目 1.儿科护士的心理素质不包括 选项 ['A.良好的记忆能力'] 选项 ['B.良好的观察能'] 选项 ['C.良好的思维能力'] 选项 ['D.良好的模仿能力'] 选项 ['E.良好的人际沟通能力'] 题目 2.婴儿对某些传染病有一定的抵抗能力,主要是通过胎盘从母体中获得 选项 ['A.IgA'] 选项 ['B.SIgA'] 选项 ['C.IgE'] 选项 ['D.IgG'] 选项 ['E.IgM'] 题目 3.小儿从母体获得的抗体从何时起日渐消失 选项 ['A.生后1~2个月'] 选项 ['B.生后3~4个月'] 选项 ['C.生后5~6个月'] 选项 ['D.生后7~8个月'] 选项 ['E.生后10~12个月'] 题目 4.婴幼儿护理技术要求不包括下列哪项 选项 ['A.按婴幼儿疾病特点给予治疗及护理'] 选项 ['B.掌握婴幼儿各种生理特点和疾病特点'] 选项 ['C.练就一手过硬的静脉穿刺技术'] 选项 ['D.掌握各项辅助检查正常值'] 选项 ['E.小婴儿应予配奶、喂奶、喂药'] 题目 5.儿科护理学的范围不包括下列哪项:A.儿科临床护理工作 选项 ['B.儿童时期卫生保健工作'] 选项 ['C.儿科护理科学研究'] 选项 ['D.熟练掌握护理操作技能'] 选项 ['E.儿童的早期教育'] 题目 6.造成婴幼儿易患呼吸道感染的原因是 选项 ['A.血清中IgA缺乏'] 选项 ['B.分泌型IgA缺乏'] 选项 ['C.血清中IgG缺乏'] 选项 ['D.血清中IgM缺乏'] 选项 ['E.细胞免疫功能低下'] 题目 7.婴儿期是指 选项 ['A.生后脐带结扎至1周岁'] 选项 ['B.出生后至1周岁'] 选项 ['C.生后1个月至1周岁前'] 选项 ['D.生后2周岁以内'] 选项 ['E.1~3周岁'] 题目 8.幼儿期是指 选项 ['A.生后29天至1周岁'] 选项 ['B.1~3周岁前'] 选项 ['C.2~5周岁'] 选项 ['D.3~5周岁'] 选项 ['E.4~6周岁'] 题目 9.根据小儿年龄不同,将小儿时期分为 选项 ['A.7个时期'] 选项 ['B.6个时期'] 选项 ['C.5个时期'] 选项 ['D.4个时期'] 选项 ['E.8个时期']
看起来没有问题
现在我打算将当前匹配出来的文本数据存储 成字典形式的结构化数据:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 # 保存最终的结构化数据 question_type2data = OrderedDict() # 从word文档的“一、单项选择题”开始遍历数据 title2options = {} options = [] for paragraph in doc.paragraphs[0:]: # 去除空白字符,将全角字符转半角字符,并给括号之间调整为中间一个空格 line = black_char.sub("", paragraph.text).replace( "(", "(").replace(")", ")").replace(".", ".").replace("()", "( )") # 对于空白行就直接跳过 if not line: continue if title_rule.match(line): options = title2options.setdefault(line, []) elif option_rule.match(line): options.extend(option_rule_search.findall(line)) else: chinese_nums_match = chinese_nums_rule.match(line) if chinese_nums_match: question_type = chinese_nums_match.group(1) title2options = question_type2data.setdefault(question_type, OrderedDict())
遍历结构化字典储存 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 result = [] max_options_len = 0 for question_type, title2options in question_type2data.items(): for title, options in title2options.items(): result.append([question_type, title, *options]) options_len = len(options) if options_len > max_options_len: max_options_len = options_len df = pd.DataFrame(result, columns=["题型", "题目"]+[f"选项{i}" for i in range(1, max_options_len+1)]) # 题型可以简化下,去掉选择两个字 df['题型'] = df['题型'].str.replace("", "") df.head() print(df) try: df.to_excel(r'D:\垃圾项目\test.xlsx', sheet_name='Sheet1', index=False, header=True) except: print("写入成功!")
全部代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 import pandas as pd import re from docx import Document from collections import OrderedDict doc = Document("D:\垃圾项目\儿科.docx") # for i, paragraph in enumerate(doc.paragraphs[:55]): # print(i, paragraph.text) black_char = re.compile("[\s\u3000\xa0]+") chinese_nums_rule = re.compile("[一二三四]、(.+)") title_rule = re.compile("\d+.") option_rule = re.compile("[ABCDEF]") option_rule_search = re.compile("^.+?$") # 保存最终的结构化数据 question_type2data = OrderedDict() # 从word文档的“一、单项选择题”开始遍历数据 title2options = {} options = [] for paragraph in doc.paragraphs[0:]: # 去除空白字符,将全角字符转半角字符,并给括号之间调整为中间一个空格 line = black_char.sub("", paragraph.text).replace( "(", "(").replace(")", ")").replace(".", ".").replace("()", "( )") # 对于空白行就直接跳过 if not line: continue if title_rule.match(line): options = title2options.setdefault(line, []) elif option_rule.match(line): options.extend(option_rule_search.findall(line)) else: chinese_nums_match = chinese_nums_rule.match(line) if chinese_nums_match: question_type = chinese_nums_match.group(1) title2options = question_type2data.setdefault(question_type, OrderedDict()) result = [] max_options_len = 0 for question_type, title2options in question_type2data.items(): for title, options in title2options.items(): result.append([question_type, title, *options]) options_len = len(options) if options_len > max_options_len: max_options_len = options_len df = pd.DataFrame(result, columns=["题型", "题目"]+[f"选项{i}" for i in range(1, max_options_len+1)]) df.head() print(df) #打印出来看看处理的结果是否正确 try: df.to_excel(r'D:\垃圾项目\test.xlsx', sheet_name='Sheet1', index=False, header=True) except: print("写入成功!")
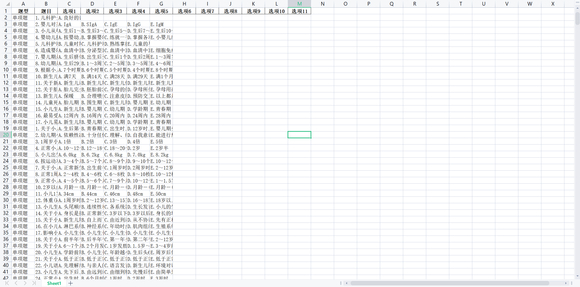
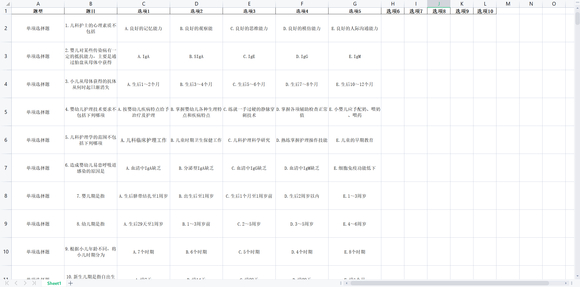
最终效果
有一些格式不规范套不上正则 但是并不多大概十几道题 总的来说解决的大部分的工作量
稍微调整一下excal
结语 这个工作连学习带调试大概花费了三个小时时间,一个晚自习加第二天研学的一半时间。时间花费并不算多,但是通过写代码解决了一件生活中常见的问题,把技术转换成了生产力 我还是很高兴的。帮舍友解决了问题,自己也得到了锻炼和成就感,最近学习任务又多又重,前一段时间看了赵文凯的博客感触颇深,其实我也很迷茫,因为学习本身艰难且短期看没有什么收益 。我能够做到这件事情,虽然这是一件微不足道的小事,但也能说明我日以继日做的努力没有白白的浪费,更加坚定了我继续学习下去的信心。用那个相传甚广的交大学生生存法则的话来说,能够支持你学习下去的一定是你对科学技术的好奇心。 也希望各位也能够保持初心砥砺前行。
最后让我再说一句“振翅云顶之上,汲目星辰大海! ”