pandas学习笔记 Series serirs的创建 1 2 3 4 5 6 7 8 9 10 11 12 13 import pandas as pdpd.Series(np) 传入一个可迭代对象 可以指定index作为键值 >>> d = {'a' : 1 , 'b' : 2 , 'c' : 3 }>>> ser = pd.Series(data=d, index=['a' , 'b' , 'c' ])>>> sera 1 b 2 c 3 dtype: int64
切片和索引 与字典一样 Series可以通过index来查找对应的值
1 2 3 4 5 6 7 8 d = {'name' : "xiaoming" , 'age' : 18 , 'tel' : 1008010 } t3 = pd.Series(d) print (t3['name' ])print (t3[0 ])xiaoming xiaoming
同样的 我们可以对其进行切片以及离散的索引取值
Series也有where方法但与numpy有些不同
DataFrame DataFrame是一种二维数据
DataFrame的基础属性 1 2 3 4 5 6 7 8 9 10 11 df.shape df.dtypes df.ndim df.index df.columns df.values DataFrame整体情况查询 df.head(3 ) df.info() df.describe()
DataFrame的切片索引 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 Input: df = pd.DataFrame(np.arange(12 ).reshape(3 ,4 )) Output: 0 1 2 3 0 0 1 2 3 1 4 5 6 7 2 8 9 10 11 行索引叫index axis = 0 列索引叫 columns axis =1 与之前一样我们可以指定行索引和列索引 df = pd.DataFrame(np.arange(12 ).reshape(3 ,4 ),index=list ('abc' ),columns=list ('wxyz' )) print (df)OutPut: w x y z a 0 1 2 3 b 4 5 6 7 c 8 9 10 11 选择某一列 df["CountAnimalName" ] 同时选择行和列 df[:100 ]["CountAkimalName" ] 还有更多的经过pandas优化过的选择方式 df.loc 通过标签索引行数据 df.iloc 通过位置获取列数据 print ("*" *100 )print (df.loc["a" , "z" ])print (df.loc["a" ])print (df.loc[:, "y" ])print ("*" *100 )print (df.iloc[0 , 1 ])print (df.iloc[:,1 ])print (df.iloc[[0 ,1 ],[1 ,2 ]])**************************************************************************** 3 w 0 x 1 y 2 z 3 Name: a, dtype: int32 a 2 b 6 c 10 Name: y, dtype: int32 **************************************************************************** 1 a 1 b 5 c 9 Name: x, dtype: int32 x y a 1 2 b 5 6 与之前相同也有 df[df["Count_AnimalName" ]>800 ]
DataFrame的字符串方法
DataFrame的排序 1 2 3 4 5 6 7 8 9 10 11 12 df.sort_value() def sort_values ( self, by, axis: Axis = 0 , ascending=True , inplace: bool = False , kind: str = "quicksort" , na_position: str = "last" , ignore_index: bool = False , key: ValueKeyFunc = None , ):
缺失数据的处理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 pd.isnull 可以帮助我们判断这个值是否为NAN pd.notnull 可以判断不是nan的值 处理方式1 :删除NaN所在的行列 dropna (axis=0 ,how=any ,inplace=False ) how 传入any 或all 全部为nan就删除或者部分nan删除 inplace 是选择是否在原地进行替换 处理方式2 : 填充数据 t.fillna(t.mean()),t.fiallna(t.median()),t.fillna(0 ) 处理为0 的数据: t[t==0 ] = np.nan 当然并不是每次为0 的数据都需要处理 计算平均值等情况,nan是不参与计算的,但是0 会
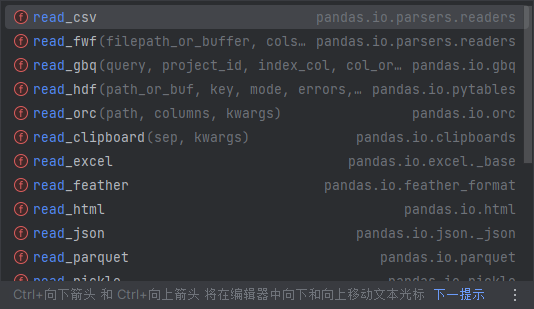
Pandas读取外部数据 1 df = pd.read_csv(path) 打开csv文件
有很多方法打开各式数据
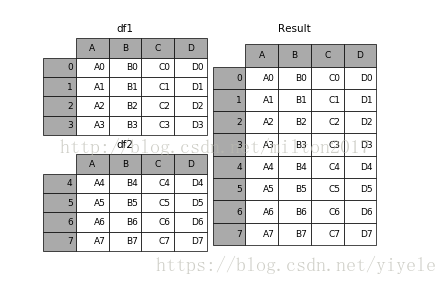
数据的合并和分类聚合 合并
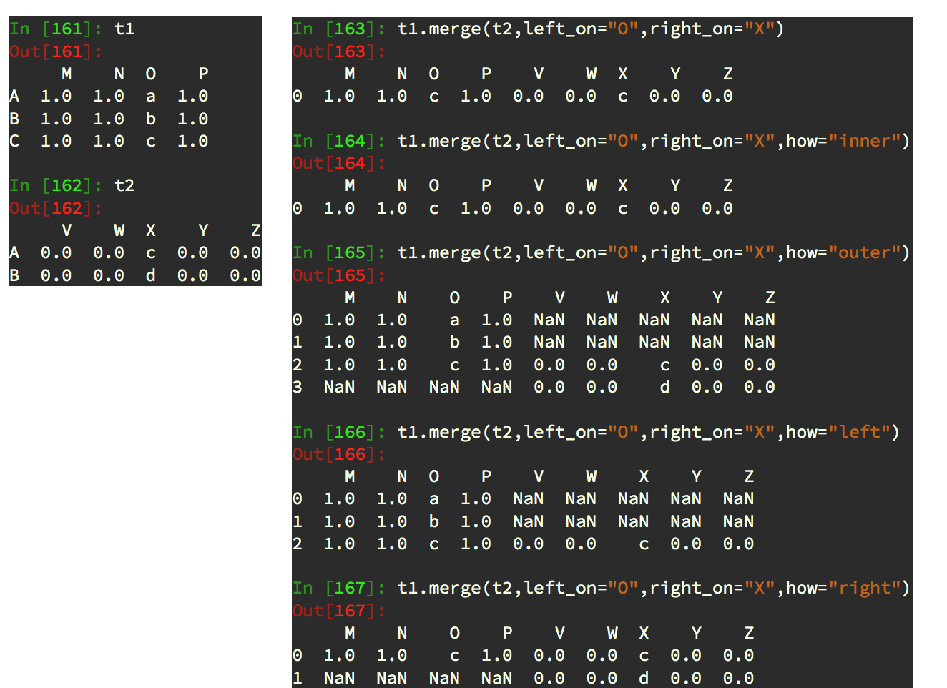
merge按照指定的列把数据按照一定的方式合并到一起
如果两个集有相同的列表头那就可以用 on参数指定‘df1.merge(df3.on=”a”,how=”outer”)
取交集的本质是判断相同行的值是否相等 如果相等把这一行的另外的数据补到后边
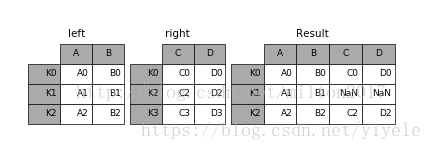
默认为inner交集
outer 并集,NAN补全
left 左边为准NAN补全
right 右边为准,NAN补全
分组 在pandas中类似的分组的操作我们有很简单的方式来完成
df.groupby(by="columns_name")
grouped是一个DataFrameGroupBy对象,是可迭代的grouped中的每一个元素是一个元组元组里面是(索引(分组的值),分组之后的DataFrame)
DataFrameGroupBy对象有很多经过优化的方法
函数名
说明
count
分组中非NA值的数量
sum
非NA值的和
mean
非NA值的平均值
median
非NA值的算术平均数
std、var
无偏(分母为n-1)标准差和方差
min、max
非NA的最小值最大值
如果我们需要对不同的列进行分组统计
grouped = df.groupby(by=[df["Country"],df["State/Province"]])
很多时候我们只希望对获取分组之后的某一部分数据,或者说我们只希望对某几列数据进行分组
获取分组之后的某一部分数据:
df.groupby(by=[“Country”,”State/Province”])[“Country”].count()
对某几列数据进行分组:
df["Country"].groupby(by=[df["Country"],df["State/Province"]]).count()
观察结果,由于只选择了一列数据,所以结果是一个Series类型
t1 = df[["Country"]].groupby(by=[df["Country"],df["State/Province"]]).count()
t2 = df.groupby(by=["Country","State/Province"])[["Country"]].count()
以上的两条命令结果一样和之前的结果的区别在于当前返回的是一个DataFrame类型
索引和复合索引
简单的索引操作:获取index:df.index
指定index :df.index = [‘x’,’y’]
重新设置index : df.reindex(list(“abcedf”))
指定某一列作为index :df.set_index(“Country”,drop=False) drop为False时被指定为index的那一列不会被删除
返回index的唯一值:df.set_index(“Country”).index.unique() 因为有unique 说明index的值可以重复
当复合重复时索引会省略多余部分
series复合索引
如果要直接用level标签里的标签作为索引有:
DataFrame复合索引
Pandas时间序列 不管在什么行业,时间序列都是一种非常重要的数据形式,很多统计数据以及数据的规律也都和时间序列有着非常重要的联系
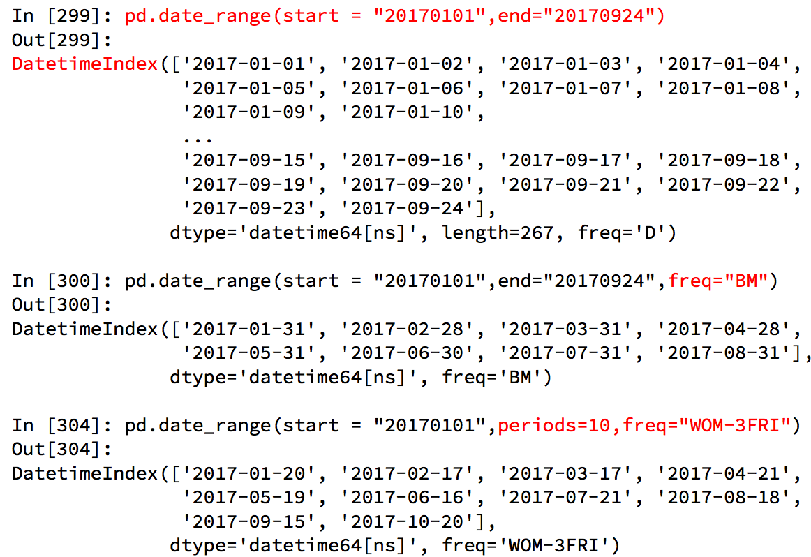
生成一段时间范围 pd.date_range(start=None, end=None, periods=None, freq='D')
start和end以及freq配合能够生成start和end范围内以频率freq的一组时间索引
start和periods以及freq配合能够生成从start开始的频率为freq的periods个时间索引
1 2 3 index=pd.date_range("20170101" ,periods=10 ) df = pd.DataFrame(np.random.rand(10 ),index=index)
我们可以使用pandas提供的方法把时间字符串转化为时间序列
df["timeStamp"] = pd.to_datetime(df["timeStamp"],format="")
format参数大部分情况下可以不用写,但是对于pandas无法格式化的时间字符串,我们可以使用该参数,比如包含中文
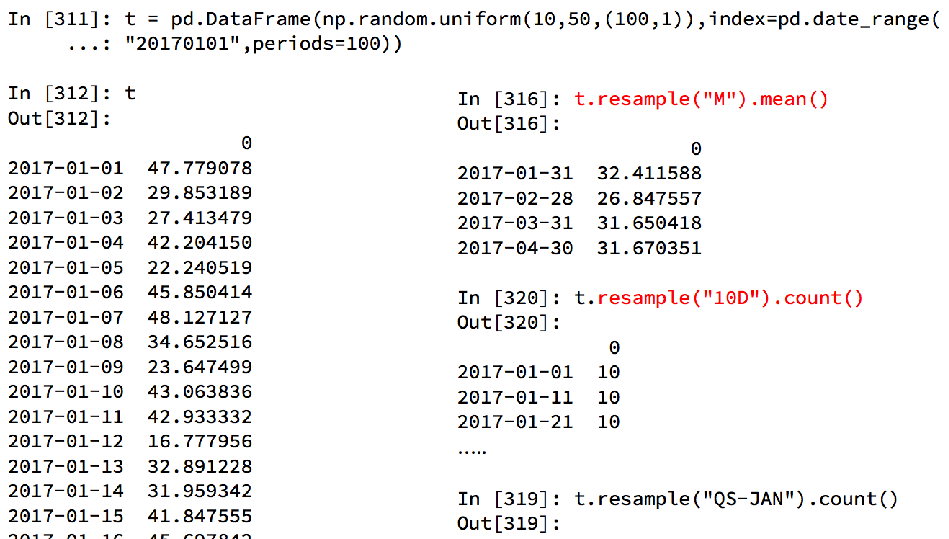
pandas重采样 重采样 :指的是将时间序列从一个频率转化为另一个频率进行 处理的过程,将高频率数据转化为低频率数据为降采样 ,低频率转化为高频率为升采样
pandas提供了一个resample的方法来帮助我们实现频率转化
PeriodIndex 之前所学习的DatetimeIndex可以理解为时间戳
PeriodIndex可以理解为时间段
periods = pd.PeriodIndex(year=data["year"],month=data["month"],day=data["day"],hour=data["hour"],freq="H")
如果给这个时间段降采样
data = df.set_index(periods).resample("10D").mean()
pandas常用接口 1、维度查看: 2、数据表基本信息(维度、列名称、数据格式、所占空间等): 3、每一列数据的格式: 4、某一列格式: 5、空值: 6、查看某一列空值: 7、查看某一列的唯一值: 8、查看数据表的值: 9、查看列名称: 10、查看前5行数据、后5行数据: 三、数据表清洗 1、用数字0填充空值: 2、使用列prince的均值对NA进行填充: 1 df['prince' ].fillna(df['prince' ].mean())
3、清除city字段的字符空格: 1 2 df['city' ]=df['city' ].map (str .strip) 1
4、大小写转换: 1 df['city' ]=df['city' ].str .lower()
5、更改数据格式: 1 2 df['price' ].astype('int' ) 1
6、更改列名称: 1 df.rename(columns={'category' : 'category-size' })
7、删除后出现的重复值: 1 2 df['city' ].drop_duplicates() 1
8 、删除先出现的重复值: 1 df['city' ].drop_duplicates(keep='last' )
9、数据替换: 1 df['city' ].replace('sh' , 'shanghai' )
四、数据预处理 1 2 3 4 5 df1=pd.DataFrame({"id" :[1001 ,1002 ,1003 ,1004 ,1005 ,1006 ,1007 ,1008 ], "gender" :['male' ,'female' ,'male' ,'female' ,'male' ,'female' ,'male' ,'female' ],"pay" :['Y' ,'N' ,'Y' ,'Y' ,'N' ,'Y' ,'N' ,'Y' ,],"m-point" :[10 ,12 ,20 ,40 ,40 ,40 ,30 ,20 ]})
1、数据表合并 1.1 merge 1 2 3 4 df_inner=pd.merge(df,df1,how='inner' ) df_left=pd.merge(df,df1,how='left' ) df_right=pd.merge(df,df1,how='right' ) df_outer=pd.merge(df,df1,how='outer' )
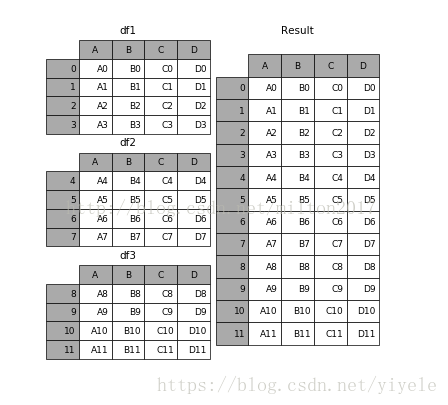
1.2 append 1 2 result = df1.append(df2) 1
1.3 join 1 2 result = left.join(right, on='key' ) 1
1.4 concat 1 2 3 pd.concat(objs, axis=0 , join='outer' , join_axes=None , ignore_index=False , keys=None , levels=None , names=None , verify_integrity=False , copy=True )
objs︰ 一个序列或系列、 综合或面板对象的映射。如果字典中传递,将作为键参数,使用排序的键,除非它传递,在这种情况下的值将会选择
(见下文)。任何没有任何反对将默默地被丢弃,除非他们都没有在这种情况下将引发 ValueError。
axis: {0,1,…},默认值为 0。要连接沿轴。
join: {‘内部’、 ‘外’},默认 ‘外’。如何处理其他 axis(es) 上的索引。联盟内、 外的交叉口。
ignore_index︰ 布尔值、 默认 False。如果为 True,则不要串联轴上使用的索引值。由此产生的轴将标记
0,…,n-1。这是有用的如果你串联串联轴没有有意义的索引信息的对象。请注意在联接中仍然受到尊重的其他轴上的索引值。
join_axes︰ 索引对象的列表。具体的指标,用于其他 n-1 轴而不是执行内部/外部设置逻辑。 keys︰
序列,默认为无。构建分层索引使用通过的键作为最外面的级别。如果多个级别获得通过,应包含元组。
levels︰ 列表的序列,默认为无。具体水平 (唯一值) 用于构建多重。否则,他们将推断钥匙。
names︰ 列表中,默认为无。由此产生的分层索引中的级的名称。
verify_integrity︰ 布尔值、 默认 False。检查是否新的串联的轴包含重复项。这可以是相对于实际数据串联非常昂贵。
副本︰ 布尔值、 默认 True。如果为 False,请不要,不必要地复制数据。
1 2 3 例子:1. frames = [df1, df2, df3] 2. result = pd.concat(frames) 12
2、设置索引列 1 2 df_inner.set_index('id' ) 1
3、按照特定列的值排序: 1 df_inner.sort_values(by=['age' ])
4、按照索引列排序: 5、如果prince列的值>3000,group列显示high,否则显示low: 1 df_inner['group' ] = np.where(df_inner['price' ] > 3000 ,'high' ,'low' )
6、对复合多个条件的数据进行分组标记 1 df_inner.loc[(df_inner['city' ] == 'beijing' ) & (df_inner['price' ] >= 4000
7、对category字段的值依次进行分列,并创建数据表,索引值为df_inner的索引列,列名称为category和size 1 pd.DataFrame((x.split('-' ) for x in df_inner['category' ]),index=df_inner.index
8、将完成分裂后的数据表和原df_inner数据表进行匹配 1 df_inner=pd.merge(df_inner,split,right_index=True , left_index=True )
五、数据提取 主要用到的三个函数:loc,iloc和ix,loc函数按标签值进行提取,iloc按位置进行提取,ix可以同时按标签和位置进行提取。
1、按索引提取单行的数值 2、按索引提取区域行数值 3、重设索引 4、设置日期为索引 1 df_inner=df_inner.set_index('date' )
5、提取4日之前的所有数据 6、使用iloc按位置区域提取数据 7、适应iloc按位置单独提起数据 1 df_inner.iloc[[0 ,2 ,5 ],[4 ,5 ]]
8、使用ix按索引标签和位置混合提取数据 1 df_inner.ix[:'2013-01-03' ,:4 ]
9、判断city列的值是否为北京 1 df_inner['city' ].isin(['beijing' ])
10、判断city列里是否包含beijing和shanghai,然后将符合条件的数据提取出来 1 df_inner.loc[df_inner['city' ].isin(['beijing' ,'shanghai' ])]
11、提取前三个字符,并生成数据表 1 pd.DataFrame(df_inner['category' ].str [:3 ])
六、数据筛选 使用与、或、非三个条件配合大于、小于、等于对数据进行筛选,并进行计数和求和。
1、使用“与”进行筛选 1 df_inner.loc[(df_inner['age' ] > 25 ) & (df_inner['city' ] == 'beijing' ), ['id' ,'city' ,'age' ,'category' ,'gender' ]]
2、使用“或”进行筛选 1 df_inner.loc[(df_inner['age' ] > 25 ) | (df_inner['city' ] == 'beijing' )['id' ,'city' ,'age' ,'category' ,'gender' ]].sort(['age' ])
3、使用“非”条件进行筛选 1 df_inner.loc[(df_inner['city' ] != 'beijing' ), ['id' ,'city' ,'age' ,'category' ,'gender' ]].sort(['id' ])
4、对筛选后的数据按city列进行计数 1 df_inner.loc[(df_inner['city' ] != 'beijing' ), ['id' ,'city' ,'age' ,'category' ,'gender' ]].sort(['id' ]).city.count()
5、使用query函数进行筛选 1 df_inner.query('city == ["beijing", "shanghai"]' )
6、对筛选后的结果按prince进行求和 1 df_inner.query('city == ["beijing", "shanghai"]' ).price.sum ()
七、数据汇总 主要函数是groupby和pivote_table
1、对所有的列进行计数汇总 1 df_inner.groupby('city' ).count()
2、按城市对id字段进行计数 1 df_inner.groupby('city' )['id' ].count()
3、对两个字段进行汇总计数 1 df_inner.groupby(['city' ,'size' ])['id' ].count()
4、对city字段进行汇总,并分别计算prince的合计和均值 1 df_inner.groupby('city' )['price' ].agg([len ,np.sum , np.mean])
八、数据统计 数据采样,计算标准差,协方差和相关系数
1、简单的数据采样 2、手动设置采样权重 1 2 weights = [0 , 0 , 0 , 0 , 0.5 , 0.5 ] df_inner.sample(n=2 , weights=weights)
3、采样后不放回 1 2 df_inner.sample(n=6 , replace=False ) 1
4、采样后放回 1 df_inner.sample(n=6 , replace=True )
5、 数据表描述性统计 1 2 df_inner.describe().round (2 ).T 1
6、计算列的标准差 7、计算两个字段间的协方差 1 2 df_inner['price' ].cov(df_inner['m-point' ]) 1
8、数据表中所有字段间的协方差 9、两个字段的相关性分析 1 2 df_inner['price' ].corr(df_inner['m-point' ]) 1
10、数据表的相关性分析 九、数据输出 分析后的数据可以输出为xlsx格式和csv格式
1、写入Excel 1 2 df_inner.to_excel('excel_to_python.xlsx' , sheet_name='bluewhale_cc' ) 1
2、写入到CSV 1 df_inner.to_csv('excel_to_python.csv' )