from langchain import PromptTemplate #用于 PromptTemplate 为字符串提示创建模板。
#默认情况下, PromptTemplate 使用 Python 的 str.format 语法进行模板化;但是可以使用其他模板语法(例如, jinja2 ) prompt_template = PromptTemplate.from_template( "Tell me a {adjective} joke about {content}." ) prompt_template.format(adjective="funny", content="chickens")
1 2 3 4 5 6 7 8
from langchain import PromptTemplate
#对于其他验证,请显式指定 input_variables 。 #在实例化期间,这些变量将与模板字符串中存在的变量进行比较,如果不匹配,则会引发异常; invalid_prompt = PromptTemplate( input_variables=["adjective"], template="Tell me a {adjective} joke about {content}." )
聊天模型的提示是聊天消息列表。 每条聊天消息都与内容相关联,以及一个名为 role 的附加参数。例如,在 OpenAI 聊天完成 API 中,聊天消息可以与 AI 助手、人员或系统角色相关联。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
from langchain.prompts import ChatPromptTemplate
#ChatPromptTemplate.from_messages 接受各种消息表示形式。 template = ChatPromptTemplate.from_messages([ ("system", "You are a helpful AI bot. Your name is {name}."), ("human", "Hello, how are you doing?"), ("ai", "I'm doing well, thanks!"), ("human", "{user_input}"), ])
messages = template.format_messages( name="Bob", user_input="What is your name?" )
除了使用上一个代码块中使用的(类型、内容)的 2 元组表示形式外, 还可以传入 or BaseMessage 的 MessagePromptTemplate 实例。
from langchain.prompts import ChatPromptTemplate from langchain.prompts.chat import SystemMessage, HumanMessagePromptTemplate
template = ChatPromptTemplate.from_messages( [ SystemMessage( content=( "You are a helpful assistant that re-writes the user's text to " "sound more upbeat." ) ), HumanMessagePromptTemplate.from_template("{text}"), ] )
from langchain.chat_models import ChatOpenAI
#设置代理 import os os.environ['http_proxy'] = 'http://127.0.0.1:10809' os.environ['https_proxy'] = 'http://127.0.0.1:10809'
llm = ChatOpenAI() llm(template.format_messages(text='i dont like eating tasty things.'))
from langchain.prompts.few_shot import FewShotPromptTemplate from langchain.prompts.prompt import PromptTemplate
#这里我们用字典来表示一个例子,每个示例都应该是一个字典,其中键是输入变量,值是这些输入变量的值。 examples = [ { "question": "Who lived longer, Muhammad Ali or Alan Turing?", "answer": """ Are follow up questions needed here: Yes. Follow up: How old was Muhammad Ali when he died? Intermediate answer: Muhammad Ali was 74 years old when he died. Follow up: How old was Alan Turing when he died? Intermediate answer: Alan Turing was 41 years old when he died. So the final answer is: Muhammad Ali """ }, { "question": "When was the founder of craigslist born?", "answer": """ Are follow up questions needed here: Yes. Follow up: Who was the founder of craigslist? Intermediate answer: Craigslist was founded by Craig Newmark. Follow up: When was Craig Newmark born? Intermediate answer: Craig Newmark was born on December 6, 1952. So the final answer is: December 6, 1952 """ }, { "question": "Who was the maternal grandfather of George Washington?", "answer": """ Are follow up questions needed here: Yes. Follow up: Who was the mother of George Washington? Intermediate answer: The mother of George Washington was Mary Ball Washington. Follow up: Who was the father of Mary Ball Washington? Intermediate answer: The father of Mary Ball Washington was Joseph Ball. So the final answer is: Joseph Ball """ }, { "question": "Are both the directors of Jaws and Casino Royale from the same country?", "answer": """ Are follow up questions needed here: Yes. Follow up: Who is the director of Jaws? Intermediate Answer: The director of Jaws is Steven Spielberg. Follow up: Where is Steven Spielberg from? Intermediate Answer: The United States. Follow up: Who is the director of Casino Royale? Intermediate Answer: The director of Casino Royale is Martin Campbell. Follow up: Where is Martin Campbell from? Intermediate Answer: New Zealand. So the final answer is: No """ } ]
from langchain.prompts import MessagesPlaceholder,HumanMessagePromptTemplate,ChatPromptTemplate
human_prompt = "Summarize our conversation so far in {word_count} words." human_message_template = HumanMessagePromptTemplate.from_template(human_prompt)
from langchain.schema import HumanMessage,AIMessage human_message = HumanMessage(content="What is the best way to learn programming?") ai_message = AIMessage(content="""\ 1. Choose a programming language: Decide on a programming language that you want to learn.
2. Start with the basics: Familiarize yourself with the basic programming concepts such as variables, data types and control structures.
3. Practice, practice, practice: The best way to learn programming is through hands-on experience\ """)
# 导入必要的模块和类 from langchain.output_parsers import CommaSeparatedListOutputParser from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate from langchain.llms import OpenAI from langchain.chat_models import ChatOpenAI
# 导入必要的模块和类 from langchain.prompts import PromptTemplate from langchain.output_parsers import DatetimeOutputParser from langchain.chains import LLMChain from langchain.llms import OpenAI
# 导入所需的库和模块 from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate from langchain.llms import OpenAI from langchain.chat_models import ChatOpenAI from langchain.output_parsers import PydanticOutputParser from pydantic import BaseModel, Field, validator from typing importList
\# 定义一个表示演员的数据结构,包括他们的名字和他们出演的电影列表 classActor(BaseModel): name: str = Field(description="name of an actor") # 演员的名字 film_names: List[str] = Field(description="list of names of films they starred in") # 他们出演的电影列表
\# 定义一个查询,用于提示生成随机演员的电影作品列表 actor_query = "Generate the filmography for a random actor."
markdown_text = """ # 🦜️🔗 LangChain ⚡ Building applications with LLMs through composability ⚡ ## Quick Install ```bash # Hopefully this code block isn't split pip install langchain ``` As an open source project in a rapidly developing field, we are extremely open to contributions. """ md_splitter = RecursiveCharacterTextSplitter.from_language( language=Language.MARKDOWN, chunk_size=60, chunk_overlap=0 ) md_docs = md_splitter.create_documents([markdown_text])
按字符递归拆分
1 2 3 4 5 6 7 8 9 10 11 12 13
from langchain.text_splitter import RecursiveCharacterTextSplitter # This is a long document we can split up. with open('documentstore/state_of_the_union.txt') as f: state_of_the_union = f.read() text_splitter = RecursiveCharacterTextSplitter( # Set a really small chunk size, just to show. chunk_size = 100, chunk_overlap = 20, length_function = len, ) texts = text_splitter.create_documents([state_of_the_union]) print(texts[0]) print(texts[1])
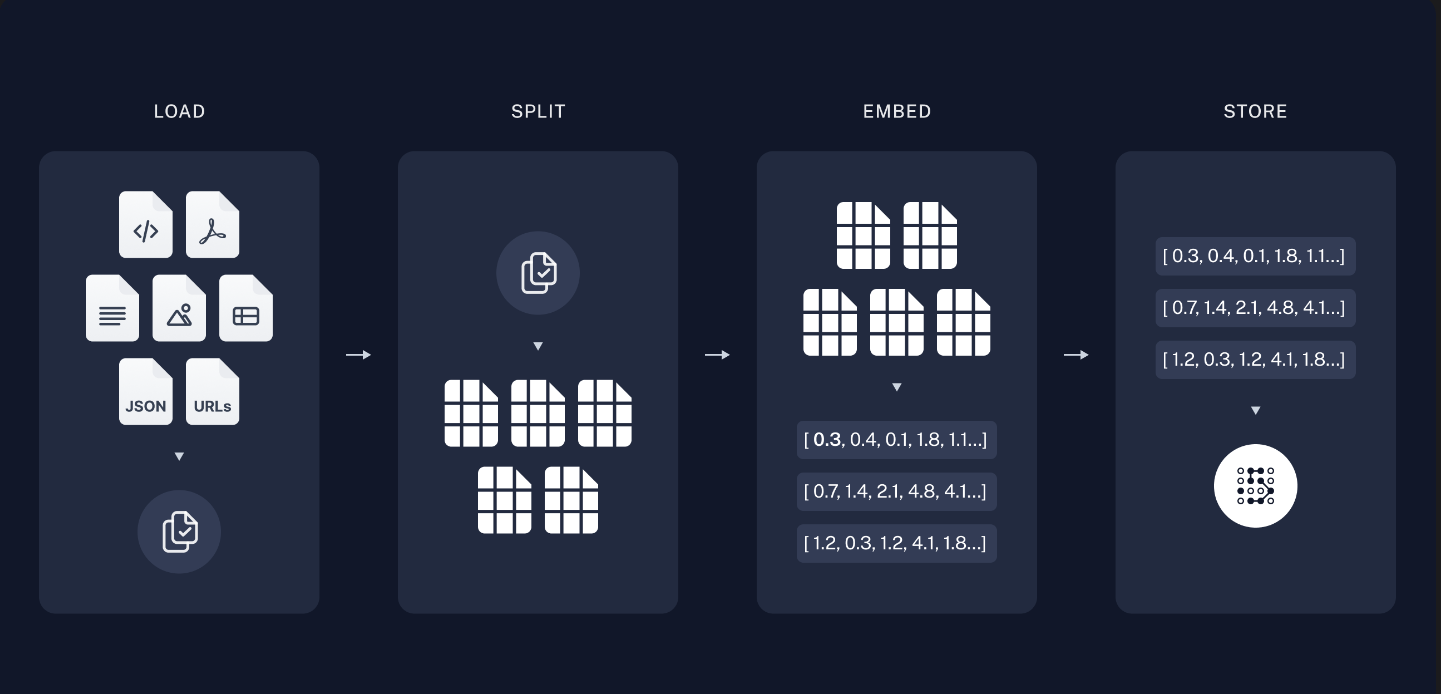
from langchain.embeddings.openai import OpenAIEmbeddings from langchain.vectorstores import Chroma \# 使用向量数据库chroma,利用openai的embadding对文本进行向量化 db = Chroma.from_texts(list_text, OpenAIEmbeddings())